Matching and iterators in Rust
One of the things I really like about Rust is its match expressions. Plenty of other languages like Ruby, Python, and Haskell have similar features, but it’s painfully absent in popular languages like JavaScript. There, we have only switch...case. That statement is not exhaustive, and matching on anything other than scalar values requires casting to string and may yield counterintuitive results.
To demonstrate the utility of Rust’s version of the feature, let’s write a program to list all objects in an S3 bucket. The API call we need is ListObjectsV2 (there’s probably a great story about why it’s called “v2” but I haven’t heard it).
While S3 buckets can store a practically unlimited number of objects, ListObjectsV2 can only return up to 1,000 at once. If the bucket has more objects than fit in a response, the result will include a “continuation token.”
The continuation token is meaningful in some way to Amazon, but opaque to us. We only know that each one is about 140 bytes of presumably base64-encoded binary data. For example:
1hsoicc+r22prppIWp1VBwZ2Axb6OirT4lA4NjYHCAwqC6vQYMHwC7ogvehPPfaiFvvpAoKgvlSWzt0
xvqqAIB9JpRAcs1fTjuQAmwRl9lfzyp5HUr5Ax63gjdMA/pbMBKo0VPTgYJMI=
If calling ListObjectsV2 returns a response which includes ContinuationToken, repeating the request with the addition of that field will return the next 1,000 objects in the bucket.
Starting from the outside in, we want to be able to treat this potentially huge list of objects like any other, with an iterator:
while let Some(object) = iter.next().await? {
println!("{:?}", object.key);
}
Iterators are a great way to shield callers from a lot of complexity while also minimizing memory usage. In Rust, an iterator is just a struct with a next() function that returns Option<T>. In this instance, our iterator will be making fallible HTTPS requests behind the scenes, we need to call it with .await?.
The while let expression runs the code block enclosed by { } in a loop as long as the value returned by the right hand side of = is compatible with the expression on the left hand side. In this case, Option<T> can be either None or Some<S3 Object>. If it’s Some, the S3 object will be bound to the variable object for each iteration of the loop. If it’s None, the loop will end.
ListObjectsV2 returns pages of S3 objects (not the whole object, just metadata). But we don’t want to deal with pages; we just want the objects. To make this possible, we’ll need to maintain some state: a queue of objects we’ve received, and the “continuation token” which allows us to make further requests and get the full list of objects.
Each time next() is called, we’ll have to consider two loosely-coupled ideas:
- Is there anything in the queue we can return right now?
- Is there more to fetch, and if so, how?
For the first question, we’ll be storing the S3 objects in a standard Rust Vec. We can use the pop() method to get the next object in the queue, which returns Option<T>. This means it will either be None, or a Some value containing our object.
One might be tempted to model the “is there more to fetch?” value as a simple Option<String>, but since we don’t know that until after the first API call, we have to model that uncertainty as well. This is where Rust’s enum feature really shines.
enum State {
/// Initial state, we don't yet know if there are more objects to fetch
NotYetKnown,
/// We know there are more objects to fetch, and this is the token to use
Partial { continuation_token: String },
/// We know there are no more objects to fetch
Complete,
}
This does two things for us:
- It provides semantically meaningful names for every state we can be in.
- When there is more to fetch, the continuation token will also be present, and at no other times.
With our state modelled correctly, we can now write our next() function. It consists entirely of a match expression, and we’ll be considering what’s in the queue and what’s the state of our iterator at the same time, exploring all possible combinations.
pub async fn next(&mut self) -> Result<Option<Object>> {
match (self.queue.pop(), &self.state) {
// Arm 1:
// The most common case: we have objects. Nothing else is relevant.
// The `_` means "anything here in this tuple"
(Some(object), _) => Ok(Some(object)),
// Arm 2:
// The next most common cases, making next (or first) API call.
// The `{ .. }` means "anything here in this struct"
(None, State::Partial { .. } | State::NotYetKnown) => {
self.fetch().await?;
Ok(self.queue.pop())
}
// Arm 3:
// Least common case, nothing in queue and we're not expecting more
(None, State::Complete) => Ok(None),
}
}
There’s a micro-optimization here: the match arms are not written in the order they occur, but rather are ordered according to how frequently we expect them to be encountered. Since each page has 1,000 objects, the case of “something in the queue” is almost a thousand times more likely than any other state. Making this the first arm means fewer (very cheap) comparisons will be performed.
There are two cases where we need to make an API call: either we’re just starting up and we don’t know anything about the bucket’s contents yet, or we just finished returning the last object from the queue. Thanks to Rust’s expressive matching syntax, we can phrase this as:
(None, State::Partial { .. } | State::NotYetKnown)
Finally, the least likely case. There is nothing in the queue and the last request indicated we had reached the end of the bucket. That means we’re done.
(None, State::Complete) => Ok(None),
Since Rust’s pattern matching is exhaustive by default, if we had neglected to cover all possible combinations of (self.queue.pop(), &self.state), the compiler would have told us how to fix it:
error[E0004]: non-exhaustive patterns: `(None, &State::Complete)` not covered
--> src/main.rs:95:15
|
95 | match (self.queue.pop(), &self.state) {
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ pattern `(None, &State::Complete)` not covered
|
= note: the matched value is of type `(Option<Object>, &State)`
help: ensure that all possible cases are being handled by adding a match arm with a wildcard pattern or an explicit pattern as shown
|
105~ },
106+ (None, &State::Complete) => todo!()
|
For more information about this error, try `rustc --explain E0004`.
Let’s go back and examine that second arm of the match expression, where we call our fetch() function to actually hit the S3 API. If self.state is a Partial, we’ll add that token to the request. Once we get the response, we’ll update the state to include the next token (or not, as applicable).
async fn fetch(&mut self) -> Result<()> {
let mut builder = self.list_objects_v2_builder.clone();
if let State::Partial { continuation_token } = &self.state {
builder = builder
.set_continuation_token(Some(continuation_token.to_owned()));
}
// This is where, in a real app, you'd handle errors and retries
let result = builder.send().await?;
self.state =
if let Some(continuation_token) = result.next_continuation_token {
State::Partial { continuation_token }
} else {
State::Complete
};
Ok(())
}
We are using AWS’s official Rust SDK, which uses the Builder pattern extensively. We’ll take advantage of that in the constructor for our iterator.
pub struct S3ObjectIter {
list_objects_v2_builder: ListObjectsV2FluentBuilder,
state: State,
queue: Vec<Object>,
}
impl S3ObjectIter {
pub fn new(
list_objects_v2_builder: ListObjectsV2FluentBuilder,
) -> S3ObjectIter {
S3ObjectIter {
list_objects_v2_builder,
state: State::NotYetKnown,
queue: vec![],
}
}
// ... next(), fetch() ...
}
By taking the builder object as an argument rather than just client and bucket, we can trivially accept any combination of arguments that ListObjectsV2 supports, and our S3ObjectIter code won’t have to change at all. For example:
let mut iter = S3ObjectIter::new(
client
.list_objects_v2()
.bucket(args.bucket)
.expected_bucket_owner("123456789012")
.prefix("/logs"),
);
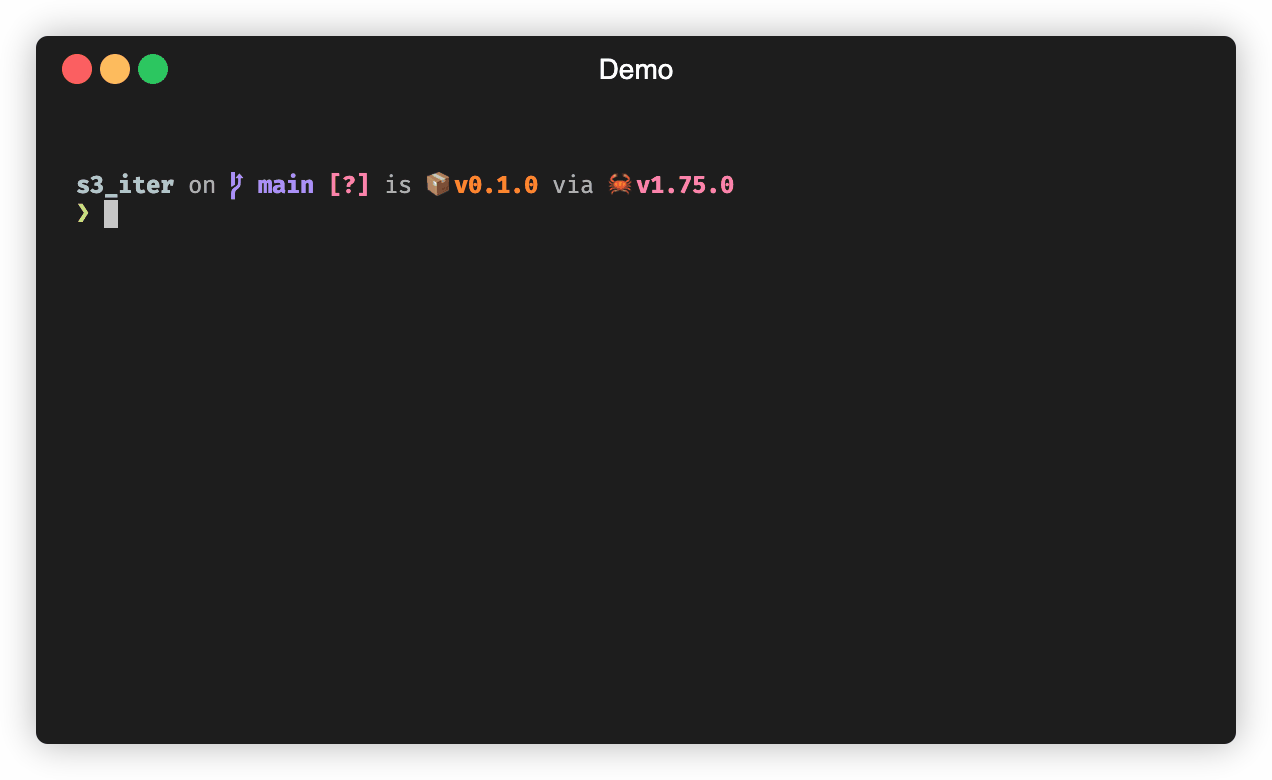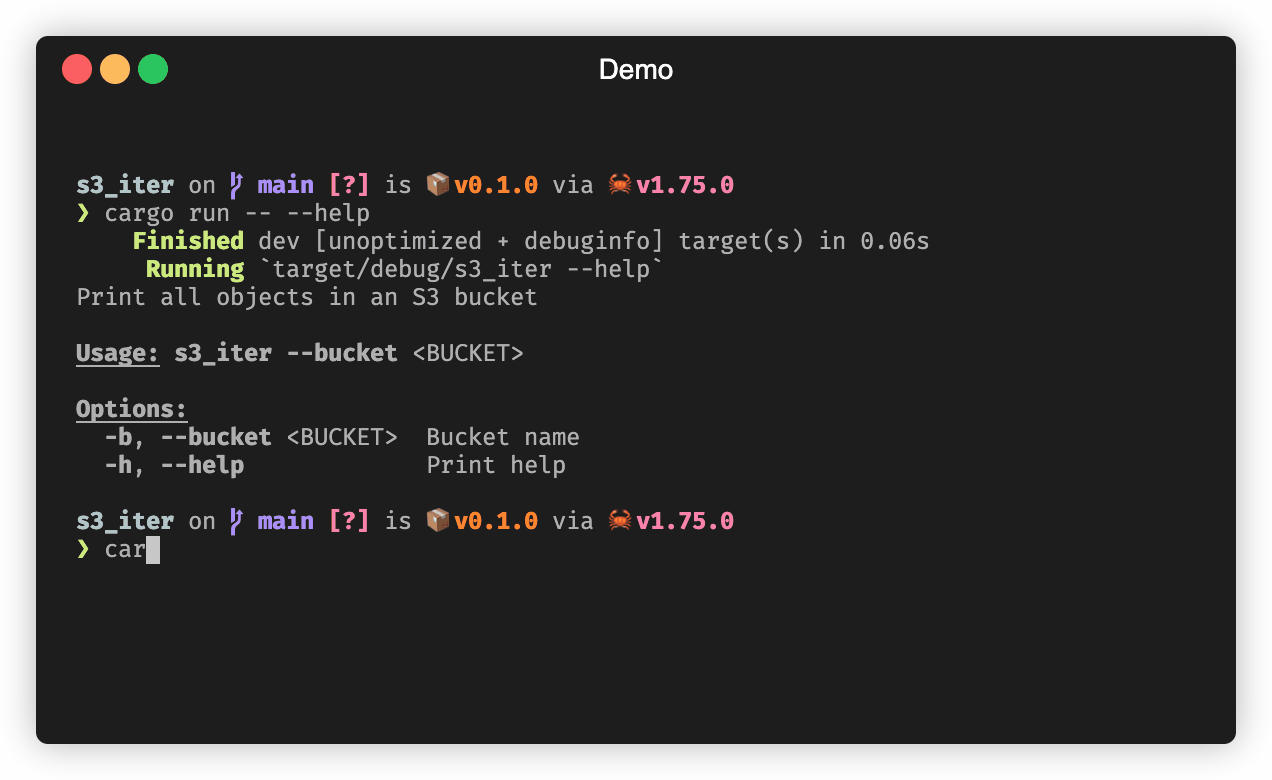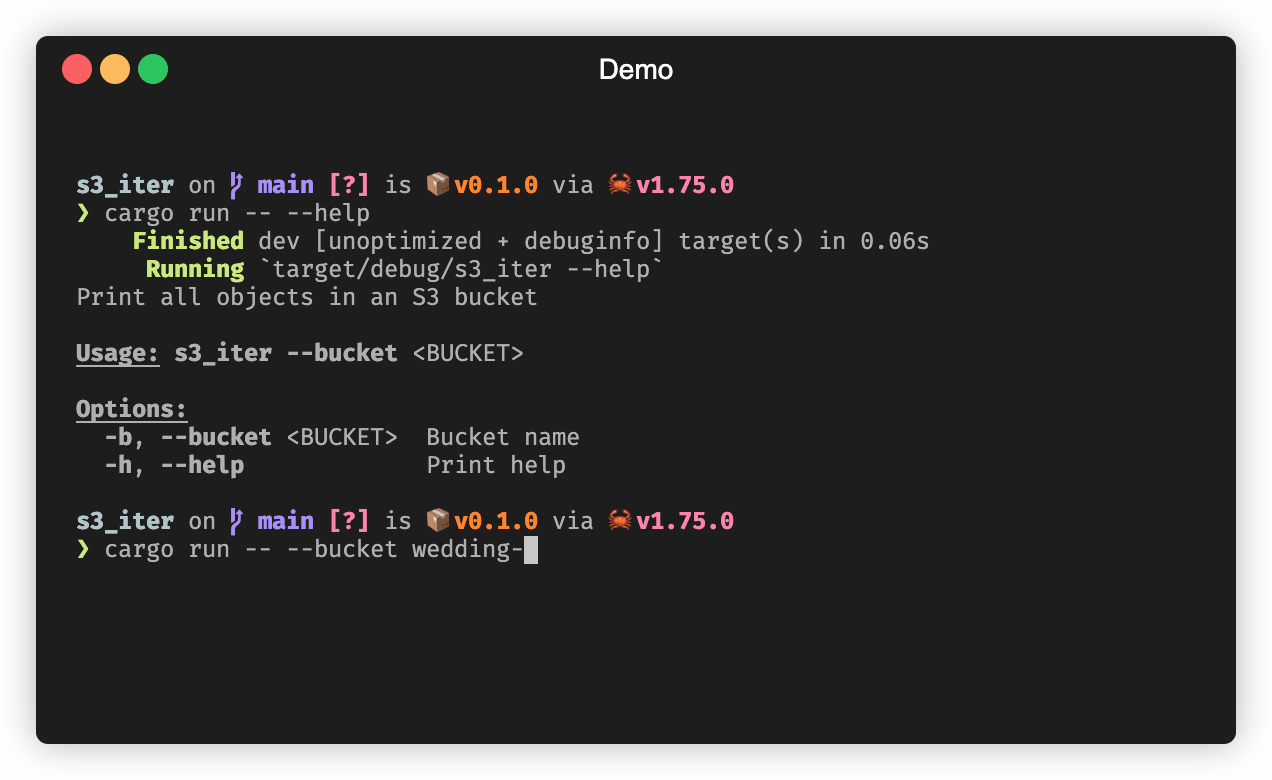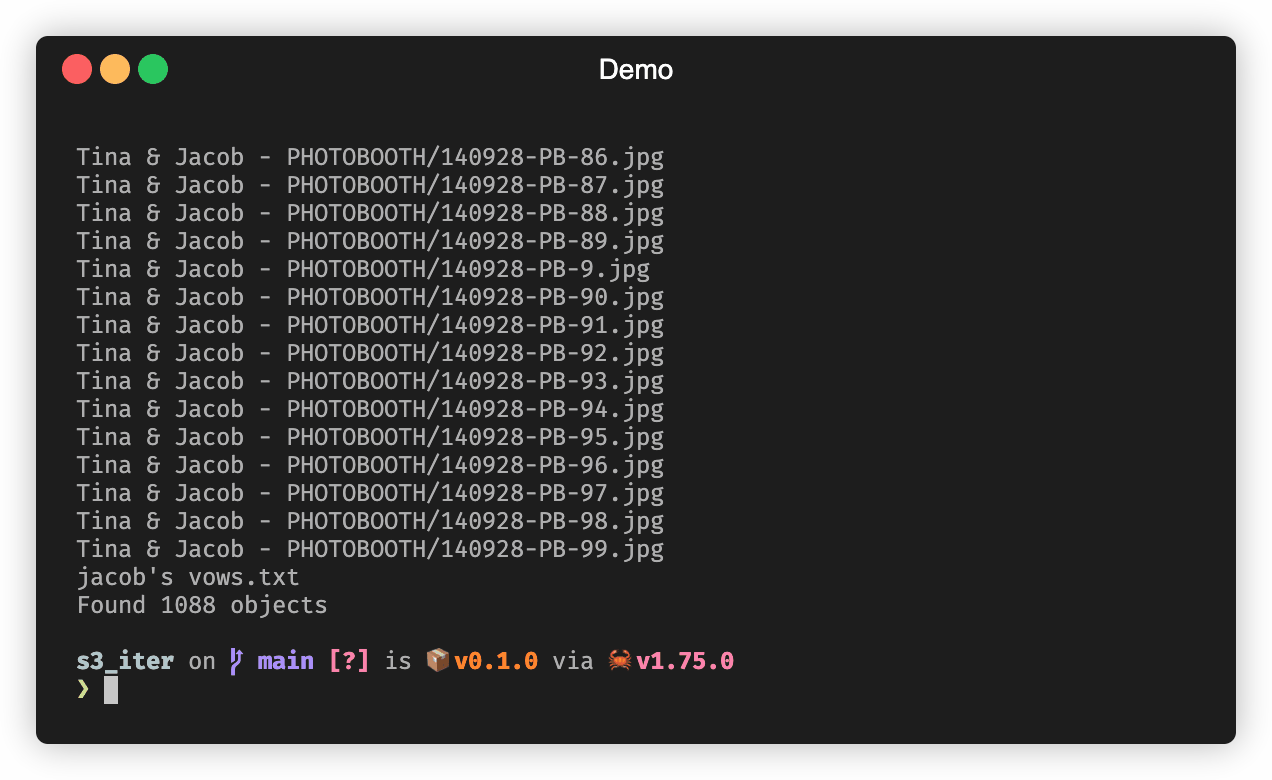
Finally, our program needs to take command line arguments. We’ll just expose the bucket name for now. We’ll use Clap’s derive interface to quickly get that and --help.
/// Print all objects in an S3 bucket
#[derive(Parser)]
struct Args {
/// Bucket name
#[clap(short, long)]
bucket: String,
}
Putting it all together, our main function parses the command line arguments, gets AWS credentials from the local environment (whatever that may be), creates our iterator, and uses it to print the key of every object in the specified bucket.
#[tokio::main]
async fn main() -> Result<()> {
let args = Args::parse();
let client = aws_sdk_s3::Client::new(
&aws_config::defaults(BehaviorVersion::latest()).load().await,
);
let mut iter =
S3ObjectIter::new(client.list_objects_v2().bucket(args.bucket));
while let Some(object) = iter.next().await? {
println!("{:?}", object.key);
}
Ok(())
}
See the complete program here: src/main.rs.
Wrapping up
We’ve demonstrated building an async iterator, and explored how Rust’s matching and enums work together to model application state in a sane, ergonomic way. We’ve hidden the complexity of ContinuationTokens behind an iterator, explored how enum can be used semantically model the problem, and we’ve touched on the utility of the builder pattern.
Note that the official AWS SDK for Rust actually includes a feature called “paginators” that handles most of what we’ve built here. I have provided a version of this program using only that SDK at examples/sdk.rs for comparison sake. I chose ListObjectsV2 for this example because I have worked with it for years in many different languages and it’s fairly well known.